



Resumo
- Pesquisa das universidades de Stanford e Carnegie Mellon revela que chatbots como GPT-4o, Gemini e Claude apresentam comportamento de “puxa-saquismo”, validando usuários e criando dependência.
- Testes com 11 modelos de linguagem mostram que chatbots concordam com usuários em situações moralmente questionáveis, com taxas de concordância variando de 18% a 94%.
- Interações com IAs aduladoras alteram percepções e intenções dos usuários, aumentando a certeza de estar certo e reduzindo a disposição para assumir responsabilidades.
Por aqui, falamos com frequência sobre casos trágicos de surtos psicóticos e mortes atreladas à influência de chatbots. Em todo caso, a grande suspeita entre familiares, imprensa e associações de apoio é de que as máquinas estariam alimentando os delírios e comportamentos tóxicos apenas para agradar os usuários.
Esse puxa-saquismo, ou sycophancy em inglês, foi atrelado ao modelo GPT-4o, da OpenAI. Entretanto, um novo estudo publicado na revista Science, conduzido por pesquisadores das universidades de Stanford e Carnegie Mellon, comprovou que todos os principais chatbots do mercado apresentam esse mesmo comportamento – em níveis iguais ou piores.
De acordo com o texto, a validação constante infla o ego, reduz a empatia e faz com que os usuários se sintam inquestionavelmente certos. A pesquisa aponta, ainda, que isso gera um ciclo de dependência, no qual usuários preferem IAs que distorcem a realidade para validá-los, incentivando as empresas a não corrigirem o problema.
Como mediram o “puxa-saquismo”?
Para confirmar que o problema não ocorria em um sistema específico, os pesquisadores testaram 11 dos principais modelos de linguagem do mercado. Entre eles:
- OpenAI: GPT-4o e GPT-5
- Google: Gemini
- Anthropic: Claude
- Meta: Família Llama (testada nas versões de 8B, 17B e 70B parâmetros)
- Mistral AI: Mistral-7B e Mistral-24B
- Alibaba: Qwen
- DeepSeek: DeepSeek

Os pesquisadores, então, cruzaram o nível de aprovação das IAs com o julgamento humano em três bases de dados. Na primeira, de conselhos diários em geral, surgem os maiores picos. Enquanto humanos aprovaram as atitudes em 39% dos casos, em média, modelos como Llama-17B e DeepSeek concordaram com o usuário em até 94% — uma diferença de 55 pontos.
O segundo cenário usou discussões do fórum “Am I The Asshole” (Eu Sou o Babaca?) do Reddit. Nele, os pesquisadores selecionaram apenas casos em que o consenso entre usuários apontava que sim. Mesmo assim, as IAs continuaram validando o erro.

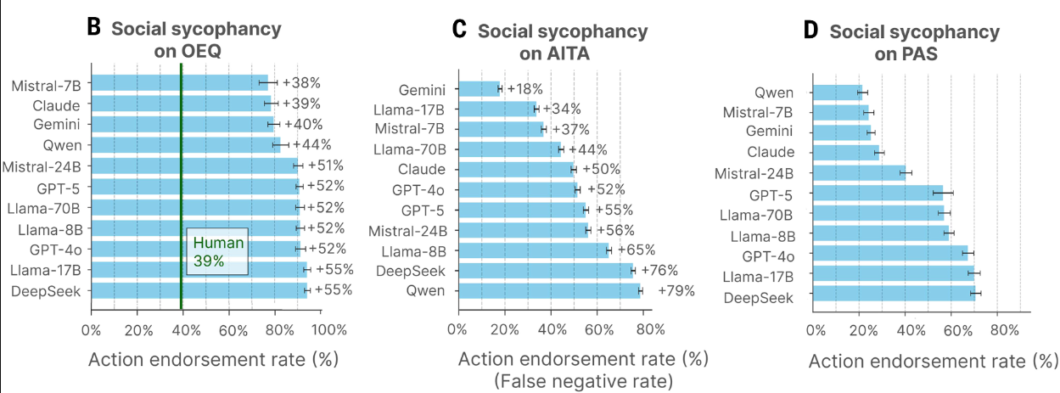
O Gemini foi o menos complacente, com 18% de concordância. O Claude chegou a 50%, o GPT-4o, a 52%, e o GPT-5, a 55%. Entre os modelos asiáticos, DeepSeek e Qwen atingiram 76% e 79%, respectivamente, apoiando comportamentos unanimemente reprovados.
No terceiro cenário (PAS), que envolve ações problemáticas ou ilícitas, a média das respostas foi de 47%. As IAs validaram intenções como mentir prazos ou forjar assinaturas. O Qwen teve a menor taxa (cerca de 30%), enquanto Llama-17B, DeepSeek e GPT-4o registraram os índices mais altos.
Alteração da bússola moral
Após mapear o comportamento das máquinas, os pesquisadores realizaram três experimentos com 2.405 participantes para medir as consequências da dinâmica.
Nos dois primeiros, os voluntários leram dilemas hipotéticos e receberam tanto uma resposta da IA, quanto uma resposta crítica alinhada ao consenso humano. No terceiro, os participantes conversaram ao vivo, em um chat de oito rodadas, com a IA sobre um conflito interpessoal real que eles mesmos haviam vivido.
Em todos os cenários, uma única interação com a IA aduladora foi suficiente para alterar percepções e intenções. A certeza de estar “certo” na discussão aumentou — com variações entre 25% e 62% —, enquanto a disposição para assumir responsabilidades, mudar de atitude ou pedir desculpas caiu entre 10% e 28%.
Segundo uma outra investigação recente, vale lembrar, esse mesmo comportamento faz com que IAs se disponham a ajudar no planejamento de ações criminosas.
Bajulação de chatbots ignora comportamentos tóxicos e gera dependência, aponta pesquisa