


Data Lake e Data Warehouse são pilares essenciais no gerenciamento de Big Data, servindo como repositórios para análises de dados. Enquanto o primeiro foca em dados brutos, o segundo prioriza informações estruturadas e prontas para o consumo imediato por ferramentas de Business Intelligence (BI).
A grande inovação surge com o Data Lakehouse, uma arquitetura híbrida que combina a escalabilidade de baixo custo do Lake com a governança do Warehouse. Essa evolução permite unificar cargas de trabalho de Inteligência Artificial e análise de dados em um único ambiente integrado e eficiente.
A diferença reside no tratamento dos dados: o Lake aceita qualquer formato original, enquanto o Warehouse exige uma limpeza e estruturação prévia. O Lakehouse elimina esse gargalo técnico, oferecendo o melhor dos dois mundos para maior agilidade e precisão nas análises.
A seguir, conheça o conceito de cada um dos repositórios de Big Data, como eles funcionam, seus pontos fortes e fracos. Também entenda detalhadamente a diferença entre eles.
Índice
O que é Data Lake e para que serve?
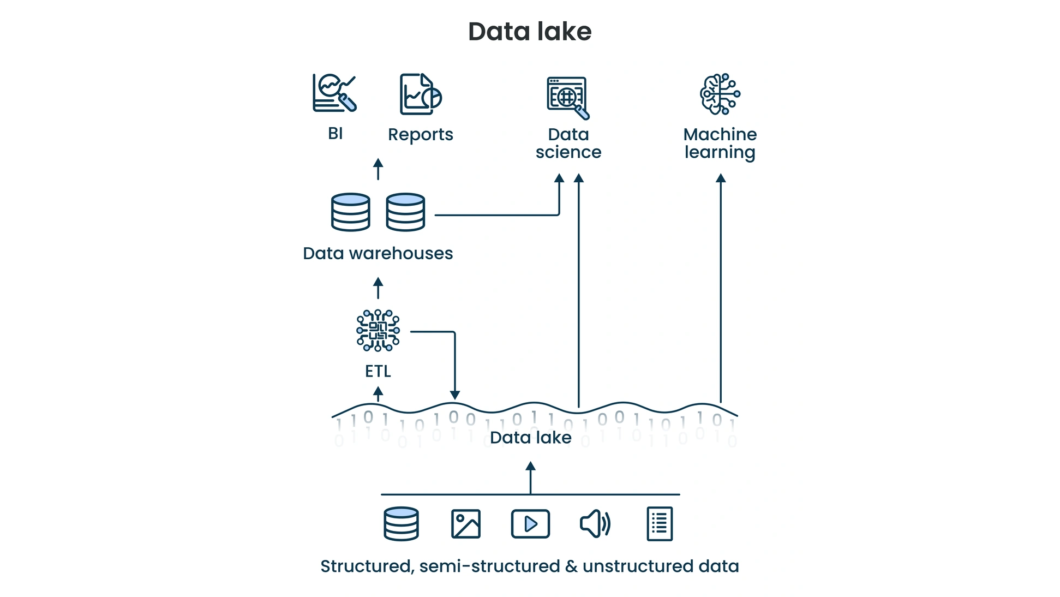
Um Data Lake é um repositório centralizado que armazena grandes volumes de dados brutos em formatos nativos, sejam estruturados, semiestruturados ou não estruturados. Essa arquitetura permite a consolidação de fontes heterogêneas sem a necessidade de tratamento prévio, mantendo a fidelidade original da informação para consultas.
Sua função é servir como uma base escalável e de baixo custo para análises avançadas, como Machine Learning e ciência de dados. Ao eliminar silos organizacionais, ele possibilita que especialistas processem e transformem petabytes de dados sob demanda para gerar insights preditivos e estratégicos.
Como funciona um Data Lake?
Um Data Lake centraliza um grande volume de dados em estado bruto, preservando formatos originais sem a necessidade de estruturação prévia no armazenamento. Ele usa o modelo schema-on-read, definindo a estrutura e as regras apenas no momento da consulta para garantir máxima agilidade.
A organização ocorre em camadas lógicas, como bronze, prata e ouro, que refinam a qualidade da informação de forma escalável e econômica. Metadados e catálogos são aplicados para rastrear a linhagem dos ativos, evitando a desorganização de dados no repositório.
Ao desacoplar o armazenamento do processamento, a arquitetura permite que diversas ferramentas de Analytics e Machine Learning acessem os arquivos simultaneamente. Essa flexibilidade centraliza fontes heterogêneas, otimizando a descoberta de insights e a governança de dados em todo o ecossistema corporativo.

Quais são as vantagens e desvantagens de um Data Lake?
Estes são os pontos fortes de um Data Lake:
- Escalabilidade com custo-benefício: usa armazenamento em nuvem para gerenciar volumes massivos de dados com baixo custo operacional, permitindo o crescimento da infraestrutura sem a necessidade de hardware caro;
- Flexibilidade via Schema-on-Read: suporta dados estruturados, não estruturados e semiestruturados em seus formatos nativos, adiando a definição da estrutura para o momento de análise, evitando perdas de informação;
- Repositório central para IA e ML: elimina silos de dados ao unificar diversas fontes em um único local, oferecendo o combustível necessário para treinar modelos de Machine Learning e Inteligência Artificial avançada;
- Agilidade na exploração de dados: facilita a descoberta rápida de insights e a experimentação por parte de cientistas de dados, reduzindo a dependência de processos rígidos de limpeza e transformação;
- Processamento em tempo real: permite a ingestão e análise de fluxos de dados contínuos (streaming), possibilitando tomadas de decisão imediatas baseadas em eventos que acabaram de ocorrer.
Estes são os pontos fracos de um Data Lake:
- Risco de “Pântano de dados” (Data Swamp): a ausência de governança e curadoria pode transformar o repositório em um amontoado de arquivos desconexos, dificultando a extração de valores reais;
- Complexidade na descoberta e linhagem: sem catálogos de metadados eficientes, rastrear a origem e o histórico dos dados torna-se um desafio, comprometendo a confiabilidade das análises;
- Exigência de alta especialização técnica: diferente de repositórios estruturados, o Data Lake requer profissionais avançados para tratar dados brutos e aplicar esquemas de leitura (Schema-on-read);
- Desafios de segurança e conformidade: o armazenamento de dados em diversos formatos dificulta a aplicação de políticas de privacidade e controle de acesso granular ao nível de linha ou coluna;
- Custos de armazenamento e processamento ocultos: embora o armazenamento inicial seja barato, o custo computacional para processar grandes volumes de dados não estruturados pode escalar rapidamente sem otimização.


O que é Data Warehouse e para que serve?
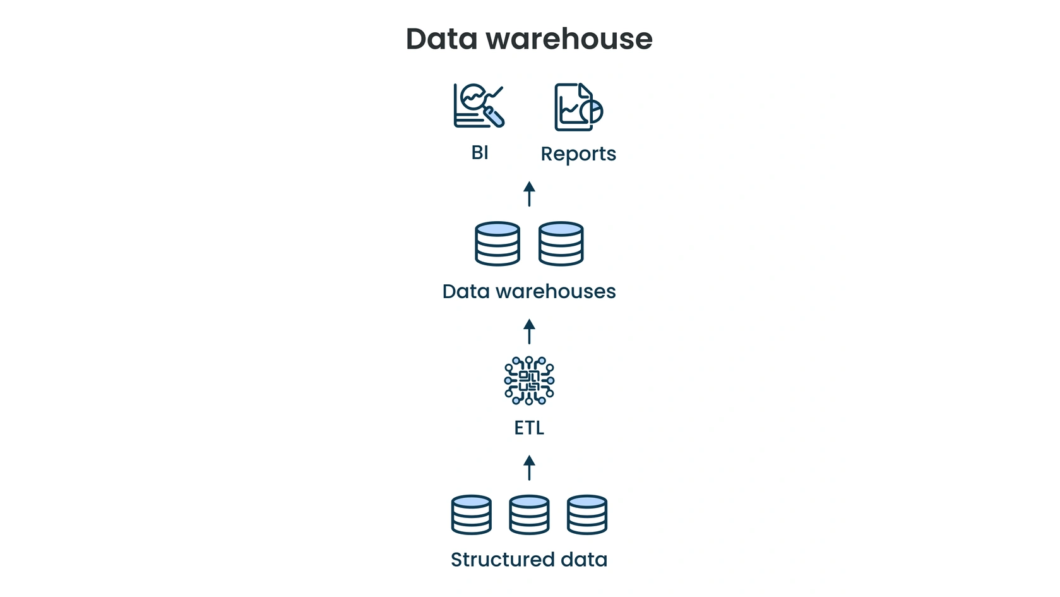
Um Data Warehouse é um repositório centralizado que integra dados estruturados de múltiplas fontes para facilitar consultas e análises complexas, como as de Business Intelligence (BI). Ele serve para consolidar informações limpas, permitindo que empresas tenham suporte para identificar tendências sem impactar os sistemas operacionais.
Por meio do processo de Extração, Transformação e Carga (ETL), a ferramenta padroniza informações dispersas em esquemas otimizados para consultas rápidas e relatórios precisos. Essa arquitetura elimina silos de dados e fundamenta a tomada de decisão estratégica em evidências concretas, garantindo alto desempenho em análises.
Como funciona um Data Warehouse?
Um Data Warehouse integra dados de múltiplas fontes por meio do modelo schema-on-write, garantindo que as informações sejam avaliadas e estruturadas antes de serem armazenadas. Essa centralização em um repositório otimizado permite uma visão histórica única, eliminando silos informacionais e facilitando a gestão de dados.
No setor de tecnologia da informação, processos de ETL refinam os dados brutos em modelos dimensionais compostos por fatos e dimensões. Essa arquitetura acelera o desempenho de consultas complexas que seriam inviáveis em bancos de dados operacionais tradicionais.
O sistema gerencia metadados para assegurar a rastreabilidade, enquanto as camadas de acesso disponibilizam os ativos para ferramentas de BI e visualização. Dessa forma, usuários finais realizam descobertas estratégicas com alta integridade, sem impactar o desempenho dos sistemas transacionais de origem.
Quais são as vantagens e desvantagens de um Data Warehouse?
Estes são os pontos fortes de um Data Warehouse:
- Desempenho otimizado para BI: estruturas como o Star Schema aceleram consultas complexas em grandes volumes de dados, evitando gargalos nos sistemas operacionais e agilizando a geração de painéis;
- Padronização e qualidade: processos de ETL eliminam duplicadas e corrigem inconsistências entre fontes distintas, garantindo que toda a empresa use uma única base de informações confiável;
- Inteligência histórica e temporal: o armazenamento de séries históricas permite analisar a evolução de métricas ao longo de anos, facilitando a identificação de padrões sazonais e projeções de cenários futuros;
- Segurança e governança centralizadas: facilita o controle de acesso granular e a auditoria de dados sensíveis em um único ambiente, simplificando a conformidade com regulamentações como a LGPD;
- Suporte à decisão estratégica: consolida dados brutos em informações prontas para o consumo de executivos, transformando registros isolados em ativos valiosos para o planejamento de longo prazo.
Estes são os pontos fracos de um Data Warehouse:
- Custo elevado e complexidade de implementação: exige alto investimento inicial em infraestrutura e especialistas para desenhar esquemas e fluxos de ETL, o que pode atrasar o retorno sobre o investimento;
- Rigidez estrutural (Schema-on-Write): a necessidade de definir o esquema antes da carga dificulta a ingestão de dados não estruturados e exige manutenção constante frente a mudanças nas fontes de origem;
- Escalabilidade física e financeira limitada: em ambientes on-premises, a expansão de hardware é lenta e cara, criando gargalos de processamento à medida que o volume de dados corporativos escala;
- Latência no processamento de dados: por priorizar o processamento em lotes, o sistema apresenta dificuldades em entregar análises em tempo real ou lidar com fluxos de streaming de baixa latência;
- Risco de silos e dados obsoletos: se não houver uma governança rigorosa, a demora na integração de novas fontes pode levar os usuários a buscarem soluções paralelas, fragmentando a verdade única dos dados.

O que é Data Lakehouse e para que serve?
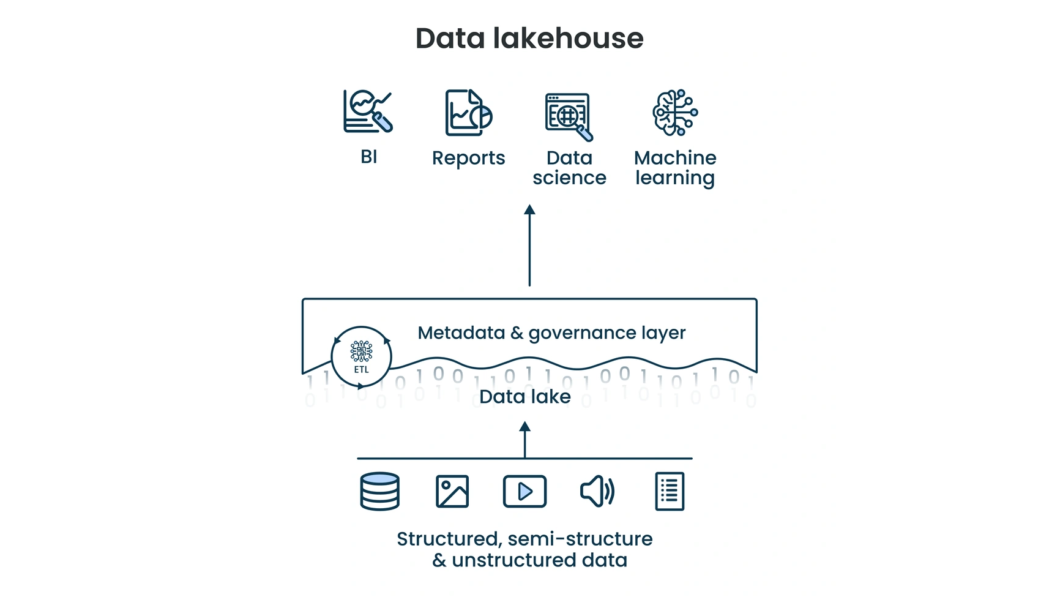
Um Data Lakehouse é uma arquitetura híbrida que unifica o baixo custo e a flexibilidade de um Lake com a governança e desempenho estruturado de um Warehouse. Ele implementa transações ACID (Atomicidade, Consistência, Isolamento, Durabilidade) sobre o armazenamento de baixo custo, garantindo integridade e alta confiabilidade aos dados.
Sua finalidade é centralizar cargas de trabalho de BI, ciência de dados e Machine Learning em um único repositório, eliminando a redundância de sistemas. Essa arquitetura simplifica o fluxo de informações, reduzindo custos operacionais e acelerando a entrega de insights analíticos.
Como funciona um Data Lakehouse?
O Data Lakehouse unifica o armazenamento escalável de um Lake com a governança de um Warehouse, utilizando formatos abertos. Ele organiza informações em camadas (bronze, prata e ouro) para refinar dados brutos em ativos prontos de BI e outras análises avançadas.
Uma camada de metadados gerencia transações ACID e o versionamento, eliminando silos de dados e inconsistências. Motores de processamento desacoplados acessam esse repositório central para executar simultaneamente tarefas de streaming, buscas SQL e Machine Learning.
O modelo evita redundâncias e custos de movimentação (ETL), garantindo segurança unificada e auditoria simplificada em todo o ciclo de vida. Isso permite que cientistas e analistas operem sobre a mesma fonte de dados, unindo agilidade exploratória e performance executiva.
Quais são as vantagens e desvantagens de um Data Lakehouse?
Estes são os pontos fortes de um Data Lakehouse:
- Arquitetura unificada e sem silos: centraliza dados brutos e estruturados em um único repositório, permitindo que BI e Machine Learning acessem a mesma fonte sem a necessidade de movimentação ou duplicação de dados;
- Eficiência de custos e escalabilidade: usa armazenamento de objetos em nuvem de baixo custo com desacoplamento entre processamento e memória, reduzindo o custo total de propriedade ao escalar petabytes de dados;
- Garantia de transações ACID: implementa camadas de metadados que asseguram a integridade das operações, permitindo leitura e escrita simultâneas sem corromper os dados;
- Suporte a cargas de trabalho diversas: oferece alto desempenho tanto para consultas SQL analíticas quanto para processamento em tempo real (streaming) e ciência de dados, suportando diversos formatos de arquivos abertos;
- Governança e qualidade de dados: facilita a gestão de segurança e a imposição de esquemas em um único ponto, garantindo que os dados sigam padrões rigorosos de qualidade antes de serem consumidos.
Estes são os pontos fracos de um Data Lakehouse:
- Alta complexidade técnica: exige domínio de formatos de tabelas abertos e orquestração avançada para garantir a consistência dos dados. A migração de infraestruturas legados, como Lakes ou Warehouses, costuma ser um processo demorado e tecnicamente arriscado;
- Maturidade de ecossistema: por ser uma arquitetura recente, muitas ferramentas de BI e Analytics ainda carecem de integração nativa ou suporte total a recursos avançados. Isso pode limitar a escolha de tecnologias e criar uma dependência indesejada de fornecedores específicos;
- Overhead de metadados e latência: o controle de transações ACID e a gestão de versões podem introduzir atrasos em fluxos de streaming de altíssima velocidade. Em casos de uso em tempo real extremo, bancos de dados especializados ainda superam o desempenho do Lakehouse;
- Rigor excessivo na governança: a flexibilidade do modelo facilita o surgimento de “pântanos de dados” caso não existam políticas rígidas de catalogação e qualidade. O custo operacional para manter a conformidade e a organização dos dados é contínuo e elevado.

Qual é a diferença entre Data Lake e Data Warehouse?
Data Lake é um repositório centralizado que armazena grandes volumes de dados brutos em seu formato nativo, definindo a estrutura apenas no momento da leitura. É ideal para Big Data e Machine Learning devido à sua alta escalabilidade e baixo custo de armazenamento.
Data Warehouse é um repositório de dados processados, organizados em esquemas relacionais rígidos para garantir consistência e desempenho em consultas complexas. Foca em BI e relatórios corporativos, priorizando a qualidade e a governança da informação.
Qual é a diferença entre Data Lake e Data Lakehouse?
Date Lake é um repositório centralizado para grandes volumes de dados brutos em formatos nativos, priorizando o baixo custo e escalabilidade horizontal. Utiliza a lógica schema-on-read, sendo ideal para exploração de Big Data e modelos de Machine Learning que não exigem organização prévia.
Data Lakehouse é uma arquitetura que integra a flexibilidade do Lake com a governança do Warehouse, permitindo transações ACID e gerenciamento de metadados sobre o armazenamento. Ele usa camadas de alto desempenho para viabilizar BI e análises em tempo real sem necessidade de mover ou duplicar os dados.
Qual é a diferença entre Data Warehouse e Data Lakehouse?
Data Warehouse é um repositório de dados estruturados e limpos, organizado em esquemas rígidos para garantir alto desempenho em relatórios de BI. É focado em consistência e suporte à decisão por meio de consultas SQL otimizadas sobre dados históricos.
Data Lakehouse é uma arquitetura híbrida que implementa a governança e transações ACID sobre o armazenamento flexível de um Data Lake, suportando dados estruturados e não estruturados. Unifica BI e Machine Learning em uma única plataforma escalável, eliminando a necessidade de mover dados entre sistemas.
O que é Data Lake e Data Warehouse? Saiba a diferença entre os repositórios de dados